Think AI voices are a modern breakthrough?
They’ve actually been evolving for over 70 years.
Before digital assistants started answering questions or narrating TikToks, researchers were experimenting with ways to make computers speak. The first speech systems were clunky, robotic, and barely understood more than a handful of words. Over time, breakthroughs in machine learning, deep neural networks, and computing power turned them into something more lifelike.
Today, AI voices can mimic humans so convincingly that many people can’t tell the difference. But to understand how we got here—and where things are going next—it helps to take a look back.
Let’s rewind.
AI-Driven Speech Experiments (1950s-1960s)
The first time a machine spoke, it didn’t sound like a voice at all. It was a collection of beeps, clicks, and crude phonemes that barely formed words. But for scientists at Bell Labs and IBM, those sounds meant progress.
1939: Voder by Bell Labs
One of Homer Dudley’s most iconic inventions, the Voder was perhaps the first-ever attempt at synthetic speech by Bell Labs. It wasn’t an AI-driven system, that's for sure, but it produced speech-like sounds using a set of tone generators and filters. A trained operator controlled it manually, shaping vowels and consonants in real-time. It was an early experiment in mechanical voice synthesis, long before AI entered the picture.
1952: Audrey by Bell Labs

More than a decade after Voder, Bell Labs introduced Audrey, a system that could recognize spoken digits (zero through nine). While it might not sound revolutionary today, at the time, it was groundbreaking.
Audrey worked by analyzing the unique sound waves of spoken numbers. However, it wasn’t fluent speech recognition—it needed users to speak slowly, clearly, and consistently. Any deviation, like changes in pitch or accent, could cause errors.
Another limitation? It only worked with a single speaker at a time. Audrey had to be trained on one person’s voice, and even then, accuracy wasn’t perfect. But for the first time, a computer could listen and respond to human speech, even if in a very limited way.
1962: IBM’s Shoebox
The Shoebox was introduced at the 1962 Seattle World’s Fair and could recognize 16 spoken words, including digits and basic arithmetic commands like “plus” and “minus."
For the first time, a machine could respond to spoken input by performing mathematical calculations. You could say “four plus two,” and Shoebox would process the command, and then display the result.
Even with these early attempts, speech recognition was frustratingly limited. The systems couldn’t handle full sentences, natural speech, or even moderate variations in pronunciation. But they laid the foundation for everything that came next.
Speech Recognition Improves (1970s-1980s)
By the 1970s, computers were getting better at processing language, but they still needed rules to follow. That’s where the Hidden Markov Model (HMM) algorithm came in.
This breakthrough allowed speech recognition to work based on probabilities. Instead of matching exact sounds to words, it predicted what the next word might be. That made speech processing far more flexible. Researchers also started improving natural language processing (NLP). The goal was to help machines handle the way humans actually speak—with accents, variations, and pauses.
For the first time, speech systems weren’t limited to just a few pre-set words. They could learn patterns, adapt to different voices, and respond more naturally.
AI Voices Go Mainstream (1990s-2000s)
By the 90s, speech recognition had moved out of research labs and into consumer products. That’s when Dragon NaturallySpeaking changed everything.
1997: Dragon NaturallySpeaking
This was one of the first speech-to-text software tools that worked in real time. You could dictate full sentences, and the software would transcribe them. It was a game-changer for accessibility, professionals, and early digital assistants.
Around the same time, voice assistants were starting to appear in rudimentary forms. These weren’t the AI-driven assistants we have today. They followed strict, pre-programmed rules. But they were the first step toward something bigger.
The AI Voice Revolution (2010s-2018)
By the early 2010s, AI was starting to make speech recognition smarter, faster, and more human-like.
2011: Siri Launches
Apple introduced Siri, marking a shift in how people interacted with technology. Instead of typing, users could ask a question and get an answer.
2014: Alexa Arrives
Amazon released Alexa, integrating voice AI into smart homes. People could control music, lights, and even order groceries—all through voice commands.
2016: Google Assistant
Google took things further by introducing contextual awareness. Instead of just answering one question, it could understand follow-ups. That made conversations with AI feel more fluid.
This period marked the beginning of neural networks being used in voice AI. Machines weren’t just recognizing words anymore. They were learning how people actually spoke.
The Age of Realistic AI Voices (2018 - Today)
Things escalated fast after 2018. We can call it the AI boom. Or the AI explosion. Basically, AI voices have been moving at light speed.
- OpenAI’s ChatGPT & Large Language Models: Suddenly, AI could process language on a whole new level. Chatbots went from just answering questions to generating human-like responses, understanding context, and even maintaining tone.
- Ultra-Realistic AI Voices: AI Voice platforms like Podcastle’s 200+ AI voices or Elevenlabs allowed creators to generate ultra-realistic speech, opening up new opportunities for aspiring content creators and helping the production process at every stage.
AI-generated voices are now used for podcasts, audiobooks, marketing, and even deepfake videos. Some companies are even using them to create personalized AI assistants.
How Content Creators Use AI Voices Today
For content creators, AI voices are a massive advantage. They make it easier to generate professional voiceovers, localize content for different audiences, and speed up production.
- Faster Narration – No need to record multiple takes. AI voices generate high-quality narration instantly.
- Multilingual Content – AI can translate and dub content, making it accessible worldwide.
- Automated Podcasting & Video Creation – AI-generated dialogues help scale content production.
While AI voices aren’t replacing human narration, they are helping creators streamline their workflow.
Honorable Mention: Kempelen's Talking Machine
This one goes way back. Centuries back. We're talking 1794.
Granted, Wolfgang von Kempelen’s Talking Machine wasn’t exactly a speech recognition system, but it was an early attempt at synthetic voice production. The device used a series of bellows, tubes, and a vibrating reed to simulate human speech. Operators could adjust airflow and articulation to form simple words and phrases.
For its time, it was a fascinating experiment in mechanical speech. While it didn’t use AI (or even electricity), it showed that artificial speech was something people were actively trying to create rather than just a foreign, sci-fi concept.
How to Create AI Voices with Podcastle
The evolution of AI voices has been decades in the making, but creating one no longer requires a research lab. With Podcastle, you can generate lifelike, professional-quality AI voiceovers in minutes—no studio time, no expensive equipment, no robotic stiffness.
Whether you’re producing narrations, podcasts, voiceovers, or audiobooks, Podcastle’s 200+ AI voices deliver natural intonation, expressive pacing, and human-like delivery. The process is simple, fast, and intuitive. Here’s how to get started:
Step 1: Head to AI Voices & Start a New Project
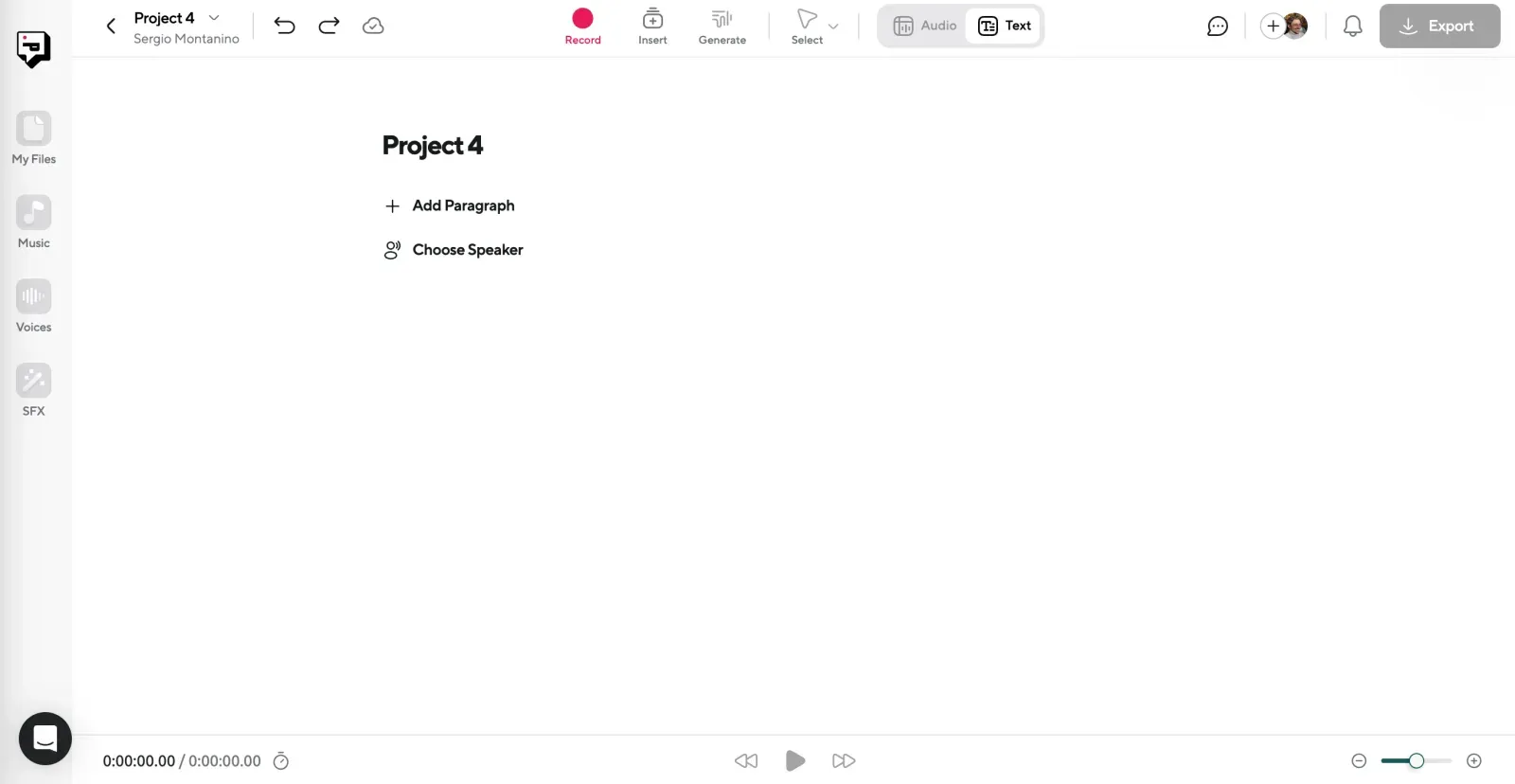
Log in to Podcastle and navigate to the AI Voices tool from your dashboard. Click Create a Project, and you’re ready to start.
Step 2: Choose Your AI Voice & Paste Your Script
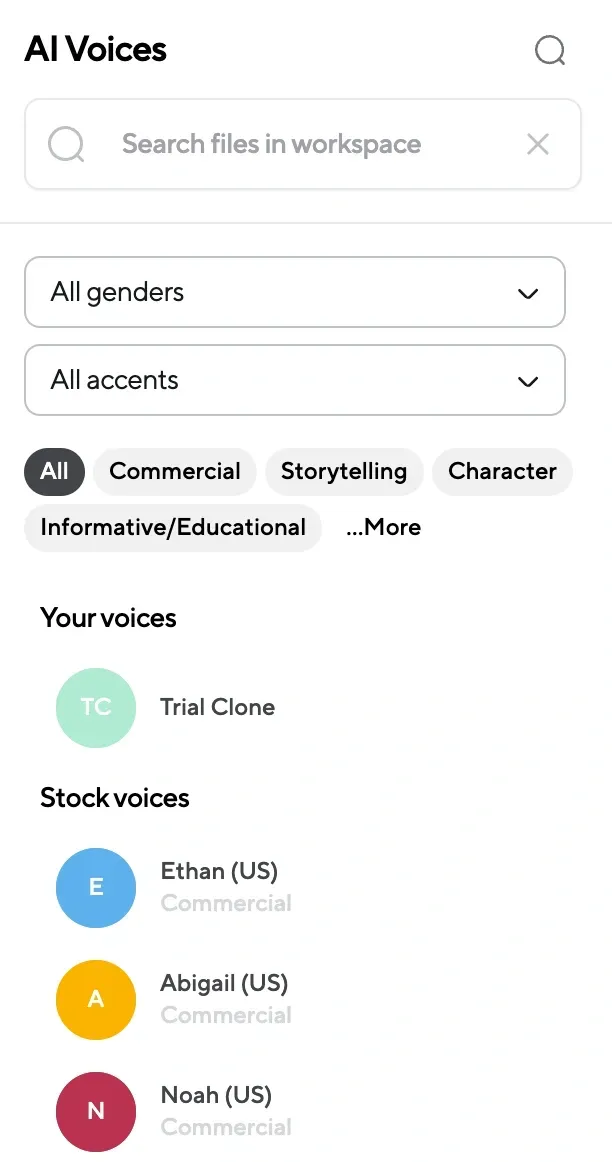
Browse through a library of over 200 AI voices, each designed for different tones and styles. Looking for a conversational voice? A polished narrator? A high-energy storyteller? There’s a perfect match for every project.
Once you’ve selected your AI voice, paste your script into the text editor.
Step 3: Generate & Listen to Your AI Voiceover
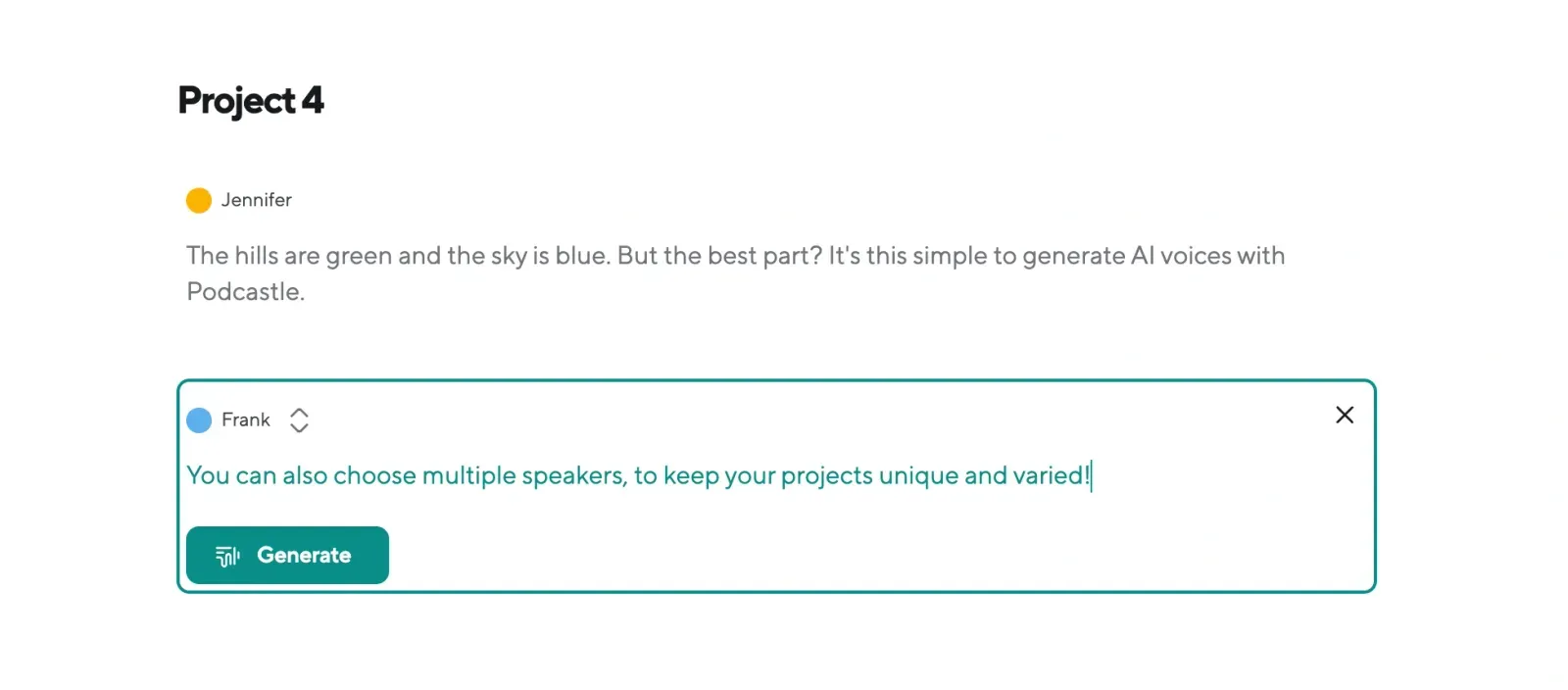
Click Generate, and Podcastle will instantly transform your text into smooth, natural-sounding speech. Unlike many AI voice tools, Podcastle applies intelligent pacing and pronunciation adjustments, ensuring the voiceover sounds like real human speech.
Preview your AI-generated voiceover and adjust as needed.
Step 4: Refine, Enhance & Export
Use Podcastle’s AI-powered tools to fine-tune your voiceover’s tone, pacing, and clarity. Features like Magic Dust AI enhance speech clarity, reduce noise, and auto-level the audio for a polished, professional result.
Once your voiceover sounds exactly how you want, export it in the format that best fits your project.
Final Thoughts: Where Are AI Voices Heading?
The way we create content is evolving fast. AI voices are helping speed up production, expand reach, and automate repetitive tasks. But they work best when paired with human creativity.
Technology can assist. The human touch makes it meaningful.