
Real-time voice products live or die by latency. Whether it’s a voice assistant, an in-game announcer, or a live translation tool, how quickly speech starts playing defines the entire user experience. For developers, milliseconds matter. The faster a model begins producing audio, the more “alive” the interaction feels.
In this benchmark, we evaluated the fastest streaming TTS models from Async Voice API, ElevenLabs, and Cartesia to better understand the balance between latency and perceived voice quality. Specifically, we measured and compared:
• Model-level latency - time spent on GPU inference only, excluding networking and application overhead.
• End-to-end latency - time from request initiation to first audio byte (TTFB) received by the client.
• Subjective audio quality - assessed using pairwise Elo ratings across multiple voice samples.
All benchmarks were executed under identical conditions, repeated multiple times for statistical confidence, and averaged across randomized prompt sets to avoid caching bias.
Methodology
To measure real-world streaming performance accurately, we used a two-layer benchmarking framework designed to separate raw model speed from full end-to-end latency. This allows us to isolate how much of the delay comes from model inference itself versus infrastructure or network overhead, a key distinction for developers optimizing real-time systems.
By measuring both layers, we capture a complete view of system performance, from infrastructure efficiency to user-perceived responsiveness. This methodology is particularly relevant for low-latency streaming use cases such as AI voice assistants, real-time dubbing, live narration, and transcription playback, where even a 100 ms delay can make interactions feel sluggish or desynchronized.
Test environment
We kept every benchmark run under the same client and network setup to make the comparison fair and repeatable. That way, any differences you see come from the models themselves, not from network noise or hardware quirks.

All evaluations were conducted using streaming API endpoints, where available, to measure first-byte latency and continuous audio throughput.
To eliminate warm-up bias, each model underwent three warm-up runs, followed by 20 measured iterations, with metrics aggregated using both median and p95 (95th percentile) values.
Model inference latency
Before accounting for API or network overhead, model inference latency reflects the raw computational speed of a text-to-speech model running on GPU hardware. This metric isolates how efficiently the model itself converts text into audio frames, independent of streaming protocols or client connectivity.
Lower inference latency typically indicates:
• Better architectural optimization
• Faster response times on equivalent GPU hardware
• Reduced serving costs when deployed at scale
The following table summarizes pure inference performance for each provider’s flagship streaming model.

Note: AsyncFlow’s architecture is optimized for L4 GPUs, achieving near floor-level inference times of ~20 ms. The lack of disclosed GPU info from ElevenLabs and Cartesia suggests their results may rely on higher-tier GPUs, which makes AsyncFlow’s efficiency-to-cost ratio stand out even more.
Streaming latency benchmark (end-to-end)
While raw inference speed shows how quickly a model can process text on a GPU, end-to-end streaming latency determines how responsive it feels in a real application. To capture both startup delay and total completion time, we measured Time to First Byte (TTFB) and total audio duration across multiple runs.
Each test consisted of:
• 20 benchmark iterations per model (after three warm-up runs to normalize cold-start effects)
• Consistent client conditions from us-central1
• HTTPS streaming requests using identical text prompts and audio configurations
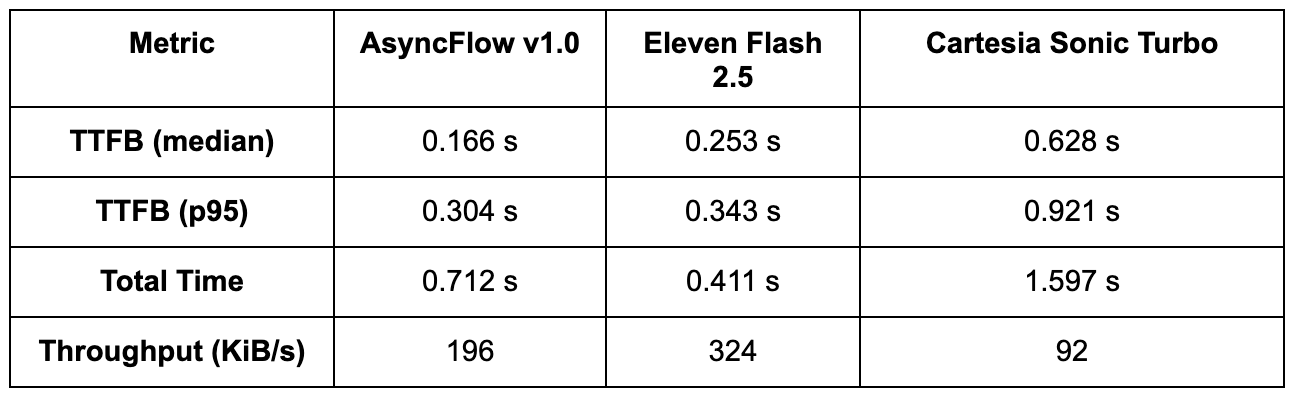
Note: p95 (95th percentile) indicates that 95% of requests completed faster than this time, providing a realistic measure of latency consistency under load.
Interpretation:
• AsyncFlow delivers audio earliest; its sub-200 ms median TTFB makes it ideal for interactive or conversational applications where users expect speech to start almost instantly.
• Eleven Flash streams at a slightly higher latency but achieves faster total completion, suggesting a more aggressive buffering or chunking strategy.
• Cartesia Sonic Turbo trails significantly behind both, with over 3× slower TTFB and lower throughput, which may limit its suitability for real-time use cases.
These measurements include model, API stack, and network latency, providing a true-to-life reflection of client-perceived streaming performance.
Benchmarking code example
To keep our measurements transparent and reproducible, we used a simple Python benchmarking script that records both time-to-first-byte (TTFB) and total response duration for each provider’s streaming API. The script sends identical text prompts, timestamps key events (request start, first audio chunk, and final byte), and aggregates the results across multiple runs to calculate median and p95 latencies.
👉 The latency benchmarking code here.
You can easily adapt this script to test your own models or infrastructure by adjusting the endpoint URLs, payload format, or concurrency parameters.
Subjective quality evaluation
This is an internal evaluation following the TTS Arena framework, focusing only on three low-latency models. In the public TTS Arena, models often target different use cases, which makes it difficult to directly compare the quality of low-latency models.
A panel of 20+ participants evaluated ~500 pairwise comparisons, each time choosing the sample that sounded more natural, expressive, and free of artifacts. The results were aggregated and normalized into Elo scores, which quantify relative preference strength rather than absolute quality.

Findings:
• Eleven Flash v2.5 achieved the highest Elo score, demonstrating slightly stronger prosody control and expressive clarity, particularly for emotional or punctuation-heavy prompts.
• AsyncFlow ranked a close second, with its performance remaining remarkably consistent and minimal robotic artifacts even under aggressive streaming latency. Considering its ~34% faster TTFB and lower serving cost, AsyncFlow offers an excellent quality-to-latency ratio.
• Cartesia Sonic Turbo trailed behind, with lower listener preference primarily due to synthetic artifacts and intonation drift at higher streaming rates.
Combined insights
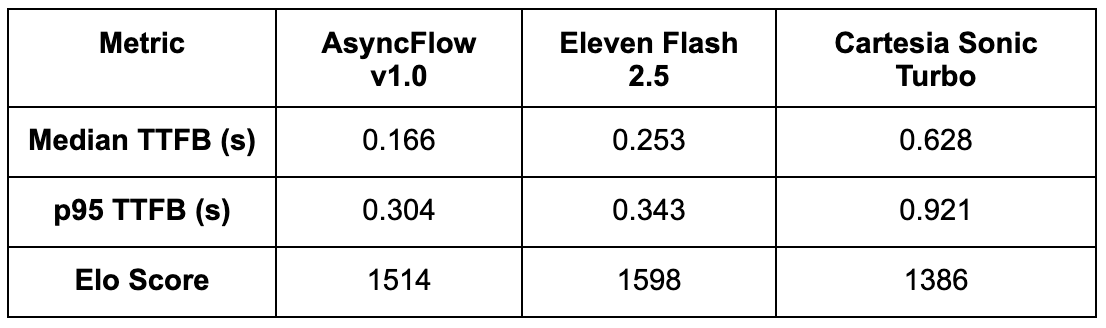
Key Takeaways:
• AsyncFlow leads decisively in time-to-first-byte (TTFB), outperforming ElevenLabs by ~34% and Cartesia by ~74% on median latency. Users hear the first sound faster, which is crucial for real-time, conversational experiences.
• Even at the 95th percentile (p95), AsyncFlow remains 11% faster than ElevenLabs and 67% faster than Cartesia, showing stability and predictability across requests, a critical property for high-concurrency applications.
• ElevenLabs retains a slight edge in subjective naturalness, particularly in expressive speech delivery. However, AsyncFlow’s close Elo score and significantly lower latency make it a highly compelling alternative.
• AsyncFlow’s architecture delivers industry-leading latency and superior cost efficiency, especially on mid-tier GPUs like the L4. For developers building real-time TTS pipelines, AsyncFlow offers the best latency-to-quality ratio among the models tested.
Why sub-200 ms latency matters
In human conversation, even short silences are noticeable. Studies show that humans begin perceiving a “pause” at around 250–300 ms of silence. For streaming TTS systems, hitting below this threshold is critical: it allows speech to feel fluid, immediate, and conversational, rather than delayed or robotic.
Achieving sub-200 ms Time-to-First-Byte (TTFB) enables a variety of real-time applications:
• Natural turn-taking in voice assistants: Users expect instant responses during interactive dialogues. Latencies above 250 ms can make a voice assistant feel sluggish or interruptive.
• Low-latency dubbing for live streaming: For live content, every millisecond counts. Faster TTS ensures that speech remains synchronized with video or event cues.
• Real-time transcription playback: Streaming text-to-speech can turn text outputs into instant audible feedback, enhancing accessibility and usability for live captioning or voice-based interfaces.
With a median TTFB of 166 ms, AsyncFlow comfortably sits below this perceptual threshold, delivering human-like responsiveness without relying on expensive, high-tier GPU hardware. This makes it particularly suitable for interactive, low-latency applications at scale.
Resources & reproducibility
• Async Voice API Developer Docs
• ElevenLabs Streaming API Docs
Conclusion
AsyncFlow demonstrates that low latency, solid quality, and cost efficiency can coexist in a single streaming TTS engine.
While ElevenLabs remains a benchmark in audio naturalness, AsyncFlow’s architectural efficiency, GPU-level optimization, and sub-200 ms TTFB make it a compelling option for developers building real-time, interactive voice systems.
For any system where perceived responsiveness defines user experience, Async Voice API currently leads the field.
Next step
Want to run these tests yourself? Explore the Async Voice API documentation and try the benchmark script with your own inputs.




